随着android gradle plugin(以下简称agp)版本的迭代,被google带进来的bug也越来越多。目前整体来看,agp 3.1.4是比较稳定的一个版本,其之后的版本多多少少都有点问题(如 agp3.2.0-3.5.0的版本R8,multidex都有问题等等),这篇文章主要介绍一下一个在2018年5月份被google带进来的bug以及如何修复它。该bug从agp 3.2.0开始存在,直到目前为止 agp 3.5.0 中依旧未修复该问题。该问题会直接影响编译速度,原本能够构建成功的一次增量构建,因为该问题,必须clean后再进行全量构建,浪费编译时间,进而降低开发效率。
这篇文章比较绕,可能会把你绕晕,如果把你绕晕了,你可以直接拉到最后面看开箱即用的解决方法。
问题描述
在agp 3.2.0以上版本,增量编译时如果之前已经参与过编译的依赖发生了改变,则会出现类重复,典型的两个场景如下:
前置条件:A模块有至少注册了两个transform,并且都支持增量编译
- A模块以project方式依赖B模块,首先对A模块进行clean后全量构建,然后将B模块发布成远程aar的形式,再将A模块中对B模块的project依赖修改成aar远程依赖,不进行clean再对A模块进行增量构建,此时会出现类重复。
- A模块以aar方式依赖B模块,首先对A模块进行clean后全量构建,再更新B模块代码重新发布到远程,不进行clean再对A模块进行增量构建,此时会出现类重复。
Transform的增量编译浅析
对于全量编译,没有什么问题,所以这里主要分析一下增量编译的关键流程。
首先了解一个文件,__content__.json文件,该文件存在于每个transform任务的输出文件夹根目录,里面记录了该transform的输入流历史相关信息,每个transform构建完成后该文件会被生成或内容被覆盖,一些输入流的信息会被序列化,下次构建的时候,如果该文件存在,则会将该文件中的内容进行反序列化生成Collection<SubStream>对象,同时会校验对应文件是否存在,体现在present字段上,如果present为false则表示之前参与编译过的文件现在被移除了,进而触发REMOVED事件。
该文件的内容大致如下:
1 | [ |
可以重点看一下这个json中的index字段,该字段决定该输入流对应的输出文件名,如果是format是JAR,则输出的是一个文件,文件名为index值.jar,如0.jar,如果format是DIRECTORY,则输出的是一个文件夹,文件名为index值,如1。
那么这个输出的文件名是怎么来的呢?我们一般是通过调用getContentLocation函数的方式获取输出的文件路径
1 | transformInvocation.getOutputProvider().getContentLocation(it.getName(), it.contentTypes, it.scopes, Format.JAR) |
最终会调用到如下函数中
1 | public synchronized File getContentLocation( |
subStreams最原始的值来自__content__.json文件的反序列化,之后会进行一定的更新操作,如果subStreams缓存中有匹配的内容,则返回匹配的内容对应的文件,如果没有匹配的内容,则重新new一个SubStream并且index进行递增。
对于全量构建时,每次调用getContentLocation基本上都是没有已经存在的SubStream,所以每次都是走从0开始的递增逻辑。
但是对应增量构建,由于之前构建产生了__content__.json文件,所以在执行transform前会先反序列化,将该文件中最大的index+1作为nextIndex的起始递增值,即假如__content__.json文件中有n个index,但是最大的index是5,则我们调用getContentLocation不再从0开始递增,而是从6开始递增。尤其注意这一个地方的特征,增量编译不一定是从0开始递增文件名。
我们再来看一段很普通不过的transform的代码,单纯的执行拷贝操作并输出各文件的相关信息。
1 | @Override |
一般情况下我们是通过调用getContentLocation函数来获取当前transform的输出文件名,它的第一个入参,我们都是传递了it.getName(),那么,这个getName()函数返回的是什么值呢?
一般来说,如果一个依赖是aar,那么这个getName()返回的就是该依赖的maven坐标显示值;如果一个依赖是project,则getName()返回的是该project的path名;如果是一个目录,比如src/main/java编译产生的class目录,则getName()返回的是该目录路径的哈希值。如果前面获取的名字与已经存在的名字存在冲突,则末尾会进行追加一定的内容防止冲突。名字生成规则可以参考如下两个函数
1 |
|
getName()返回值示例如下,典型的三种命名:
1 | io.github.lizhangqu:library:1.0.0-SNAPSHOT:20190628.005304-2 |
同时所有transform中输入流的getName()返回值与其他transform中返回的都是一样的,这一点也要尤其注意。
比如某个依赖根据如上命名规则返回的getName()是2dfc24fed878febc33c1205ca066312b4cf393b0,那么在ATransform中该依赖的getName()返回的是2dfc24fed878febc33c1205ca066312b4cf393b0,BTransform中该依赖的getName()返回的也是2dfc24fed878febc33c1205ca066312b4cf393b0,CTransform中该依赖的getName()返回的同样是2dfc24fed878febc33c1205ca066312b4cf393b0,即同一个依赖在数据流向过程中其getName()返回值保持了唯一性。
了解了以上内容后,还需要了解一个很关键的内容。
如果增量编译的时候,一个依赖文件被移除了,并且该依赖是OriginalStream类型,由于该transform消费了OriginalStream,即消费了不是由transform产生的文件,而是最原始的文件,那么,即使该transform支持增量编译,也会被判断成必须进行全量编译。
举一个例子,假如我注册了两个Transform,一个叫FirstTransform,一个叫SecondTransform,全量构建完成后,我升级了其中某一个aar再进行增量构建,这就会导致gradle认为新增了一个文件,并且同时旧版本的文件被移除了,当执行到FirstTransform时,因为产生了一个被移除的文件,并且该文件不是由transform产生的,即匹配不到相关文件,触发FirstTransform进行全量编译,但是等SecondTransform进行构建的时候,也会产生一个新增文件和一个被移除的文件,但是该被移除的文件是上一个FirstTransform产生的,即不是OriginalStream却是IntermediateStream,所以SecondTransform在其他条件都满足增量编译的情况下,此时会触发增量编译。
Bug再现
有了以上理论基础之后,我们再来看看怎么复现这个bug。
我们先来看看3.1.4的逻辑,即完全没问题的流程:
我们有一些前置条件:现有A工程和B工程,并且A工程apply了一个gradle插件,该gradle插件中注册了两个Transform,一个叫FirstTransform,一个叫SecondTransform,首先让A工程以project依赖的形式进行依赖,执行全量构建
1 | ./gradlew :A:clean :A:assembleDebug |
由于是全量构建,所以__content__.json都不存在,当调用getContentLocation获取输出文件的时候,文件名命名规则从0开始递增,假设此时有两个输入文件,并且一个jar文件,一个是目录,那么FirstTransform正常来说会产生一个jar文件和一个目录,分别为first/0.jar和first/1,假如此时B工程对应的输出为first/0.jar文件,当执行到SecondTransform时,和前面一样,也会产生一个jar文件和一个目录,分别是second/0.jar和second/1,此时B工程对应的输出为second/0.jar。注意构建过程中B工程的getName()返回的一直是B工程的project path名。
构建完成后,我们将B工程发布成远程aar的形式,然后将A工程对B工程的project依赖修改成aar依赖,执行增量构建
1 | ./gradlew :A:assembleDebug |
由于是增量构建,所以上一次构建产生的__content__.json文件存在,会进行反序列化,由于之前产生了两个文件,所以此时如果index会从2开始递增。再加上FirstTransform是第一个transform并且产生了一个新增的依赖,即B的aar依赖,此时B的aar依赖getName()返回的是该依赖的maven坐标显示值;同时移除了一个旧的依赖,即B的project依赖,其getName()返回的是B工程的project path名。此时FirstTransform会强制触发全量编译,但是此时新增的aar依赖通过getContentLocation返回的就是first/2.jar,而不再是first/0.jar或者first/1,因为缓存中并没有B的aar依赖对应的SubStream,所以文件名进行了递增操作。假如B的project依赖之前产生的是first/0.jar,那么此时FirstTransform会产生两个输出文件,即first/1和first/2.jar,而first/0.jar由于是全量构建,会被删除。
当执行到SecondTransform的时候,也会有一个新增文件和一个删除文件,即first/2.jar是新增文件,first/0.jar是删除文件,对应的由于该transform上一次构建产生的__content__.json文件存在,会进行反序列化,所以此时index会从2开始递增。因此新增文件first/2.jar获取到的输出文件为second/2.jar,因为first/2.jar对应B模块的aar依赖,其getName()返回的是其maven坐标显示值,没有缓存的SubStream与其匹配,所以命名规则进行了递增,即second/2.jar,而删除文件first/0.jar获取到的输出文件为second/0.jar是因为有已存在的SubStream与其匹配,返回其原先的文件名,该文件由于被标记成删除,所以会被我们删掉。
可能比较抽象,我们贴一下输出日志会比较好理解
全量构建的输出日志
1 | > Task :app:transformClassesWithFirstForDebug |
增量构建的输出日志
1 | > Task :app:transformClassesWithFirstForDebug |
但是以上逻辑在agp 3.2.0以上版本并不成立,在2018年5月14日的时候产生了一个提交,如下
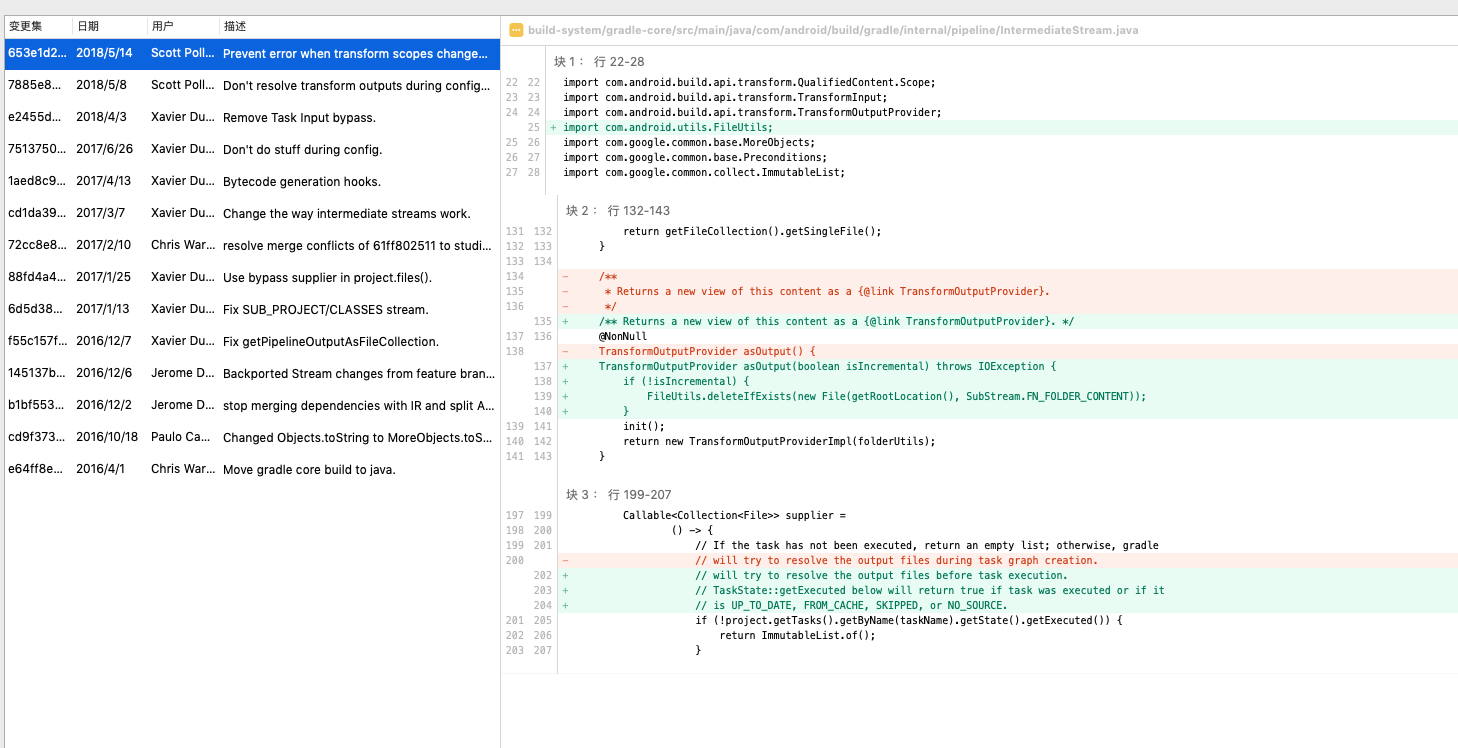
即
1 |
|
被修改成了
1 | @NonNull |
会造成什么问题呢?
我们前面说过当增量编译时,移除了一个文件,并且该文件不是transform产生而是原始文件,那么可能会触发全量编译,当触发全量编译后,在agp 3.2.0以上的版本,由于加了如上的代码,会导致FirstTransform的__content__.json文件被删除,不会进行反序列化,此时FirstTransform中文件名命名规则归0进行递增。即当执行到FirstTransform的时候,输出的依旧是first/0.jar和first/1,对于SecondTransform来说,gradle感知到的只有文件变化。依旧是增量编译,所以__content__.json文件不会被删除,会被反序列化。因为此时B工程的aar依赖返回的getName()与其project依赖返回的getName()值不一样,所以此时SecondTransform获取的输出文件名会从2开始递增。但是其输入文件名并没有发生改变,即first/0.jar和first/1,因为文件名都没变化,所以此时ADD和REMOVED都不会触发,只会触发first/0.jar的CHANGED事件,那么其对应的输出文件名是second/0.jar和second/1吗?问题就在这,很明确的告诉你,如果getContentLocation传递了it.getName(),那么此时输出文件是second/1和second/2.jar,为什么不是second/0.jar和second/1呢,因为此时依赖发生了变化,getName()自然会发生变化,缓存中找不到该name对应的SubStream,就会重新创建一个,进行index递增。
这会导致什么呢??没错,会导致原先的second/0.jar文件既没有REMOVED事件,也没有被agp删除,就会出现second/0.jar和second/2.jar共存的问题,并且这两个jar中有相同的类!!!增量构建就会出现类重复!!!
我们还是来看一下agp 3.2.0+的日志
全量构建的日志
1 | > Task :app:transformClassesWithFirstForDebug |
增量构建的日志
1 | > Task :app:transformClassesWithFirstForDebug |
编译报错
1 | java.lang.RuntimeException: java.lang.RuntimeException: com.android.builder.dexing.DexArchiveMergerException: Error while merging dex archives: /Users/lizhangqu/Desktop/android-gradle-plugin-transform-patch/app/build/intermediates/transforms/dexBuilder/debug/0, /Users/lizhangqu/Desktop/android-gradle-plugin-transform-patch/app/build/intermediates/transforms/dexBuilder/debug/4.jar, /Users/lizhangqu/Desktop/android-gradle-plugin-transform-patch/app/build/intermediates/transforms/dexBuilder/debug/2.jar |
同理,对于第二个场景,升级aar的版本或者SNAPSHOT版本发生改变,其getName()返回的maven坐标显示值也是会跟着改变的,这里注意SNAPSHOPT版本其getName()返回的值后会跟随快照版本的日期,因此不同的SNAPSHOT版本其getName()是不一样的,所以一旦升级aar或者更新SNAPSHOT,增量编译就会出现类重复。
如何修复
我们知道,产生这个问题的本质原因是因为相同的类,其归属的依赖返回的getName()发生了变化,而我们将其getName()传给了getContentLocation函数,因为值发生了变化,所以文件名进行了递增,匹配不到原先的输出文件,删除不了被移除的文件,同时又产生了一个新文件,出现类重复,那么有没有办法将getContentLocation返回值匹配到的文件变得和全量编译的时候一样呢?答案是可以的。
对于FirstTransform来讲,无论全量编译和增量编译,其输出文件都是first/0.jar和first/1,那么此时对于SecondTransform来讲,__content__.json反序列化后,如果我们将getName()传递给getContentLocation,由于getName()返回了不一样的东西,SubStream缓存中没有匹配的内容,所以命名必然会进行递增。所以此时我们不能将getName()传递给它,此时我们只需要将输入文件的绝对路径传递给它即可,这时候first/0.jar就会对应到second/0.jar而不再是second/2.jar上,为什么呢?因为用了绝对路径,全量构建时,其输入文件的绝对路径和增量构建时是一致的,都是first/0.jar的绝对路径,只是文件内容发生了变化,前后保持了唯一性,由于反序列化缓存的存在,所以它取到的名字就是second/0.jar了。
所以对于aar升级出现的类重复问题,解决方法就是将getName()传参修改为文件的绝对路径,即
将
1 | transformInvocation.getOutputProvider().getContentLocation(it.getName(), it.contentTypes, it.scopes, Format.JAR) |
修改为
1 | transformInvocation.getOutputProvider().getContentLocation(it.getFile().toString, it.contentTypes, it.scopes, Format.JAR) |
这种方式有什么弊端吗?当然有,如果你的工程中使用了n个transform,那么这n个transform都得进行修改,否则照样会出现类重复。除此之外,此方法对于project切换成aar依赖也无效,也照样会出现类重复,因此不推荐使用此方法。
当然,在android gradle plugin中,内置的transform基本都已经修改成传递输入文件的绝对路径了。很好奇为什么没有人发现这个问题,而是去修改getContentLocation的传参,并且这个bug持续了一年多都没有修复。
那么还有什么方式可以修复吗?
当然需要用一点点的黑科技,那段导致bug的代码如下
1 | @NonNull |
该函数存在IntermediateStream中,通过查看源码发现,在agp 3.2.0及之后的版本,该类都没有发生过变化。
因此我们只需要将该类实现拷出来,将导致bug的代码注释掉,如下
1 | @NonNull |
然后单独将该类独立编译成一个jar文件。
通过编写一个gradle插件,将该jar文件注入到classloader中,让其优先查找我们的补丁jar中的类完成修复,怎么样,是不是有android hotpatch的感觉。
一开始准备采用替换classloader的方式,但是测试过后发现gradle貌似对classloader进行了哈希校验,行不通,因此只能对已有的classloader采取点手段。
gradle使用的classloader是VisitableURLClassLoader,它是URLClassLoader的子类,URLClassLoader中有一个成员变量是ucp,它是URLClassPath类型,负责类和资源的查找,而URLClassPath对象中有一个loaders成员变量,它是个ArrayList,泛型是URLClassPath.Loader,查找逻辑是在ArrayList前面的会进行优先查找,所以我们只需要将这个patch文件插入到该list最前面即可,当然如果之前已经加载过该类,我们再插入也是无效的,所以这里尤其需要注意一个问题就是守护进程,因为守护进程该类之前被提前加载过,所以在测试前应该将之前的守护进程全部杀死。
1 | ./gradlew --stop |
我们的示例代码如下
1 | /** |
调用AGPTransformPatch.applyAGPTransformPatch将patch文件的URL对象传入即可
1 | if (AGPTransformPatch.shouldApplyPatch()) { |
然后应用编写好的gradle插件即可
1 | apply plugin: 'agp-transform-patch' |
如果不生效,不妨试试将守护进程杀掉!!!
柳暗花明
或许你觉得上面的方式有点重,不想hook classloader,那么有没有其他修复方式呢?爱奇艺的同学提供了一种比较简单的方式,在__content__.json文件被删除前,将其进行反序列化。__content__.json是在asOutput函数中init之前被删除,如下
1 | TransformOutputProvider asOutput(boolean isIncremental) throws IOException { |
我们只需要在delete前,提前调用init函数进行反序列化即可,那么什么时机合适呢?就是task执行前
1 | /** |
简单的几句代码也可以达到修复作用,而且比较轻量,仅仅是调用了一个protected访问符的outputStream的init函数。
在对应模块中应用该插件
1 | apply plugin: 'agp-transform-patch-by-pre-init' |
开箱即用
这里我已经将其封装成一个gradle插件,可以直接使用
对于工程目录中没有buildSrc模块的工程,可使用如下方式
1 | buildscript { |
在对应模块中应用插件
1 | apply plugin: 'agp-transform-patch' |
或者使用提前初始化修复方式的插件
1 | apply plugin: 'agp-transform-patch-by-pre-init' |
如果工程目录中有buildSrc模块,请不要使用如上的buildscript方式,而是将依赖添加到buildSrc工程的依赖中
1 | dependencies { |
然后在对应模块中应用插件
1 | apply plugin: 'agp-transform-patch' |
或者使用提前初始化修复方式的插件
1 | apply plugin: 'agp-transform-patch-by-pre-init' |
重要的事情再说一遍,如果不生效,请将守护进程杀掉,因为守护进程中该类已经被加载,插入patch后由于缓存的存在,还是使用的原来的类。
1 | ./gradlew --stop |
对应的工程见 https://github.com/lizhangqu/android-gradle-plugin-transform-patch
